❖
近年来,3D mesh的重建是3D领域研究的一个重要课题。通过强大的深度学习,很多工作能够仅通过一张RGB图片生成3D mesh。然而单个视角的输入所带来的视觉线索有限。基于单个图像的方法通常会产生粗糙的几何图形,并且无法泛化到其他的领域,例如跨类别的领域。而多视角的图片能够提供更可靠的几何信息和先验。复旦大学大数据学院提出“形变”网络(Multi-View Deformation Network, MDN)在经典方法Pixel2Mesh和Deep Implicit Surface Network的初始化基础上解决了这个问题,能够获得更好的多视角3D mesh重建效果。
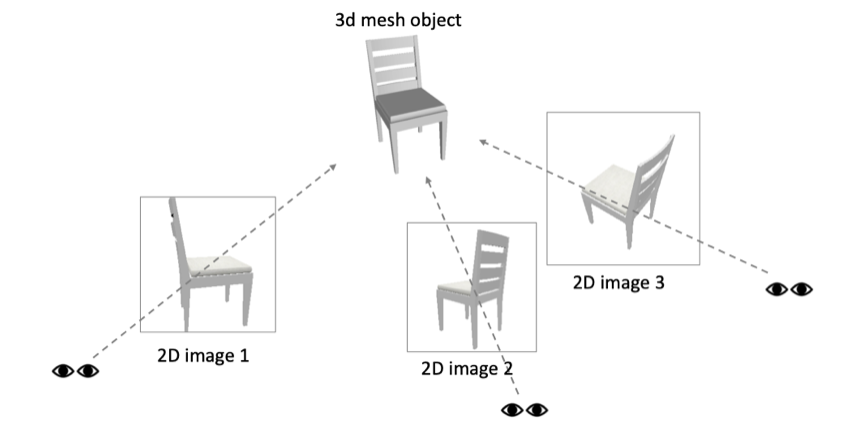
通过少量的多视角2D图片(3个视角),重建3D网格模型(mesh),是一个3D重建领域重要且困难的课题.
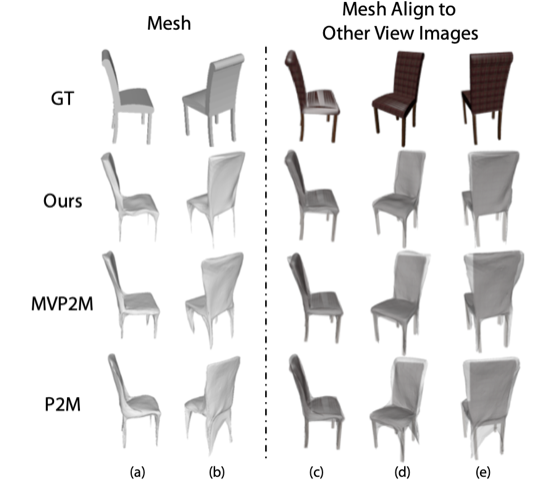
本文所提出的多视角重建算法.可以从任意角度的3张多视角图片重建出3D网格模型.与单视角算法相比(Pixel2Mesh)多视角生成结果能够更好地解决其他视角的二义性问题.
2022年4月13日(美国时间),相关研究成果以《Pixel2mesh++:基于形变的多视角3D Mesh生成》(“Pixel2Mesh++: Multi-View 3D Mesh Generation via Deformation”)为题被全球人工智能领域顶尖期刊《IEEE模式分析与机器智能汇刊》(IEEE Transactions on Pattern Analysis and Machine Intelligence,简称TPAMI)接受。该成果为多视角3D Mesh生成提供了全新的研究思路。IEEE TPAMI是计算机视觉、模式识别与人工智能领域最顶尖的SCI期刊,2021年影响因子为16.389,是中国计算机协会(CCF)评选出的为数不多的人工智能领域A类期刊之一。此前该工作还被全球人工智能领域顶级会议《国际计算机视觉大会》(IEEE International Conference on Computer Vision ICCV2019)收录。
本文不同于直接通过将图片映射到3D形状的方法,创新提出去预测一系列的形变程度,在原始的3D mesh生成结果基础上进行结果的改善。受传统多视图几何方法的启发,本文的网络对初始网格顶点位置附近的区域进行采样,并使用从多个输入图像的感知特征统计信息来推断最佳变形。此外,本文所提出的模型能够泛化到不同的基础3D mesh生成模型,例如Pixel2Mesh和基于隐函数的DISN。本文还进一步提出使用可微分渲染的方式,利用实际图片来逐步改善生成mesh的效果。为了使得多视角图片的输入到3D mesh可以直接端到端完成,本文还能够预测出相机的位姿。具体流程,形变采样和图像特征聚合的过程见下图
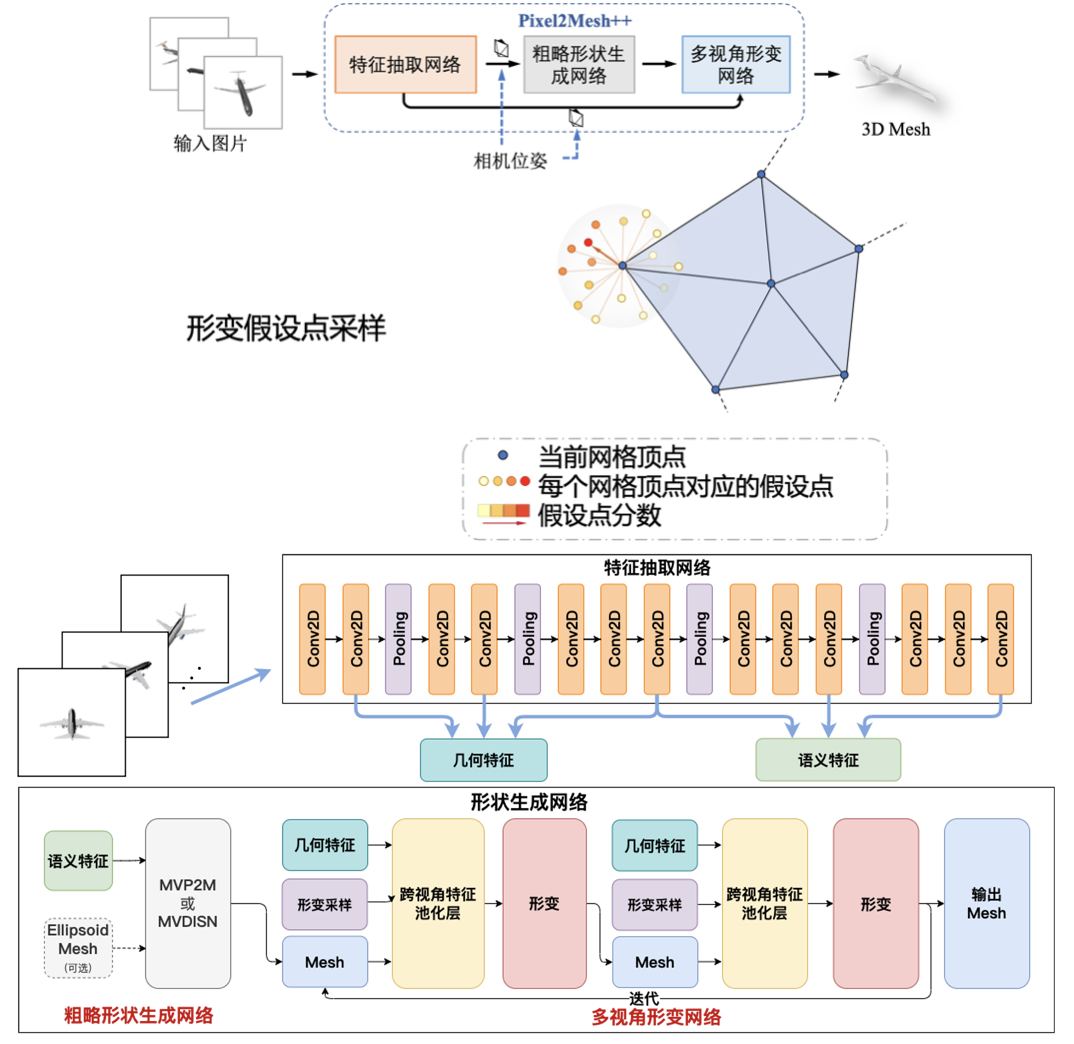
生成模型流程图.模型由特征抽取网络,粗略形状生成网络,多视角形变网络3者构成
作者简介
闻超,复旦大学大数据学院2021级硕士毕业生,硕士导师付彦伟博士。现任职于字节跳动。2014年至2018年在电子科技大学计算机科学专业攻读工学学士学位。研究方向是3D重建和人体图像合成。
曹辰捷,复旦大学大数据学院2020级博士研究生,博士导师付彦伟博士。2016年至2019年在华东理工大学计算机科学专业攻读学术硕士学位,2012年至2016年在华东理工大学计算机科学专业攻读工学学士学位。研究方向是图像生成,3D重建和计算机视觉。
其他主要合作者信息:
付彦伟老师:
http://yanweifu.github.io
张寅达老师:
https://www.zhangyinda.com
Zhuwen Li老师:
https://scholar.google. com.sg/citations?user=gIBLutQAAAAJ
薛向阳老师:
https://faculty.fudan.edu.cn/xyxue/zh_CN/more/436211/jsjjgd/index.htm
论文发表
[1] Wen, Chao, et al. Pixel2mesh++: Multi-view 3d mesh generation via deformation. Proceedings of the IEEE/CVF international conference on computer vision. 2019.