❖
小样本识别是计算机视觉与机器学习中一个重要,且困难的问题。尤其是细粒度的小样本学习,更是一个研究难点及热点。由于缺乏足够的训练数据,难以让网络掌握到充分的对象细节差异,因此神经网络在处理小样本细粒度问题上,一直都有欠缺。

许多细粒度分类问题(fine-grained classification problem)人类也很难辨别,而神经网络要在少量训练数据下辨别更是困难重重
针对小样本细粒度分类问题,一个有效的研究思路是通过图像的增广扩充小样本的训练数据集,从而训练稳定的分类器。我院付彦伟老师团队从元学习角度对这个问题进行了探索,通过设计元学习网络进行数据增广,从而有效的进行细粒度的小样本学习。
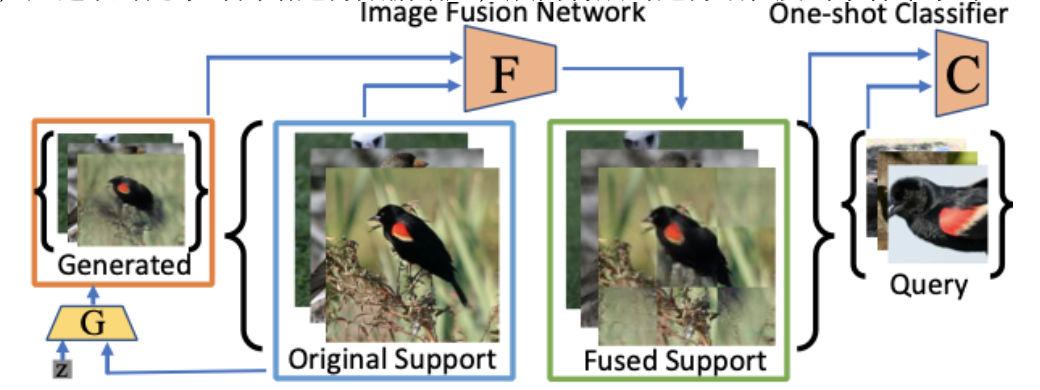
本文提出的meta-learning算法能够动态生成,学习,且融合真假样本,从而增加细粒度分类训练的难度,有效提升了分类的性能
meta-learning动态学习
●即使是使用现在最新的生成对抗网络(Generating Adversarial Networks, GAN)也很难在有限数据下生成效果非常逼真的样本。因此之前这个数据扩充方向的方法并不能很好的提供有挑战性的训练增强数据,过于简单的增强样本又难以训练出有效的分类器。
●本文提出的方法通过meta-learning动态学习以“块状”形式拼接真假样本,即“在谎言中混入真实”来增加增强数据的难度,从而能够得到更优的one-shot分类性能。同时,本文探索了如下图中多种GAN的生成方法,最终得出只微调GAN的BatchNorm(BN)层,并将真假样本混合,是一种更优的数据增广方式。正所谓,“最难辨别的谎言,是将谎言掺杂与真相中”。

(a)原图,(b)微调GAN噪声,(c)微调整个GAN模型,(d)微调GAN的BN层,(e)微调GAN的BN层且使用perceptual loss,(f)从(e)截断噪声 ,(g)合并的0-1图,(h)真假样本合并结果

本方法生成的合并权重能很好处理GAN难以生成的样本
我院付彦伟老师及合作者的相关论文“Reinforcing Generated Images via Meta-learning for One-Shot Fine-Grained Visual Recognition” (Satoshi Tsutsui, Yanwei Fu, David Crandall)被全球人工智能领域顶尖期刊《IEEE模式分析与机器智能汇刊》(IEEE Transactions on Pattern Analysis and Machine Intelligence,简称TPAMI)接收。本位第一作者Satoshi博士是2019年3-9月访问付老师研究组,本次发表的论文为访问期间合作的工作。
作者简介
Satoshi Bio: Satoshi Tsutsui is a postdoctoral research fellow at National University of Singapore (NUS). He earned a Ph.D. degree from Indiana University, USA, in 2021, while he visited Fudan University, China, in 2019. He is interested in computer vision for the visual data captured from humans’ point of view using wearable cameras (egocentric vision).
付彦伟:
http://yanweifu.github.io
David Crandall:
https://luddy.indiana.edu/contact/profile/?David_Crandall